
2022-01-26
<gap/>! Englisch ist die Lingua Franca und Basis der technischen Infrastruktur
body {
background: white;
color: black;
}library(tidyverse)
setwd("/path/to/folder/")
load("oape_stats.rda")
المجلات <- c("4770057679", "644997575", "472450345", "792756327")
المشار.اليها <- المشار.اليها %>%
filter(رقم.فهرس %in% المجلات)
write.table(المشار.اليها, file = "csv/oape_stats.csv", row.names = FALSE, quote = TRUE, sep = ",")Schriften und Sprachen des Globalen Nordens sind der Hegemon der Interfaces
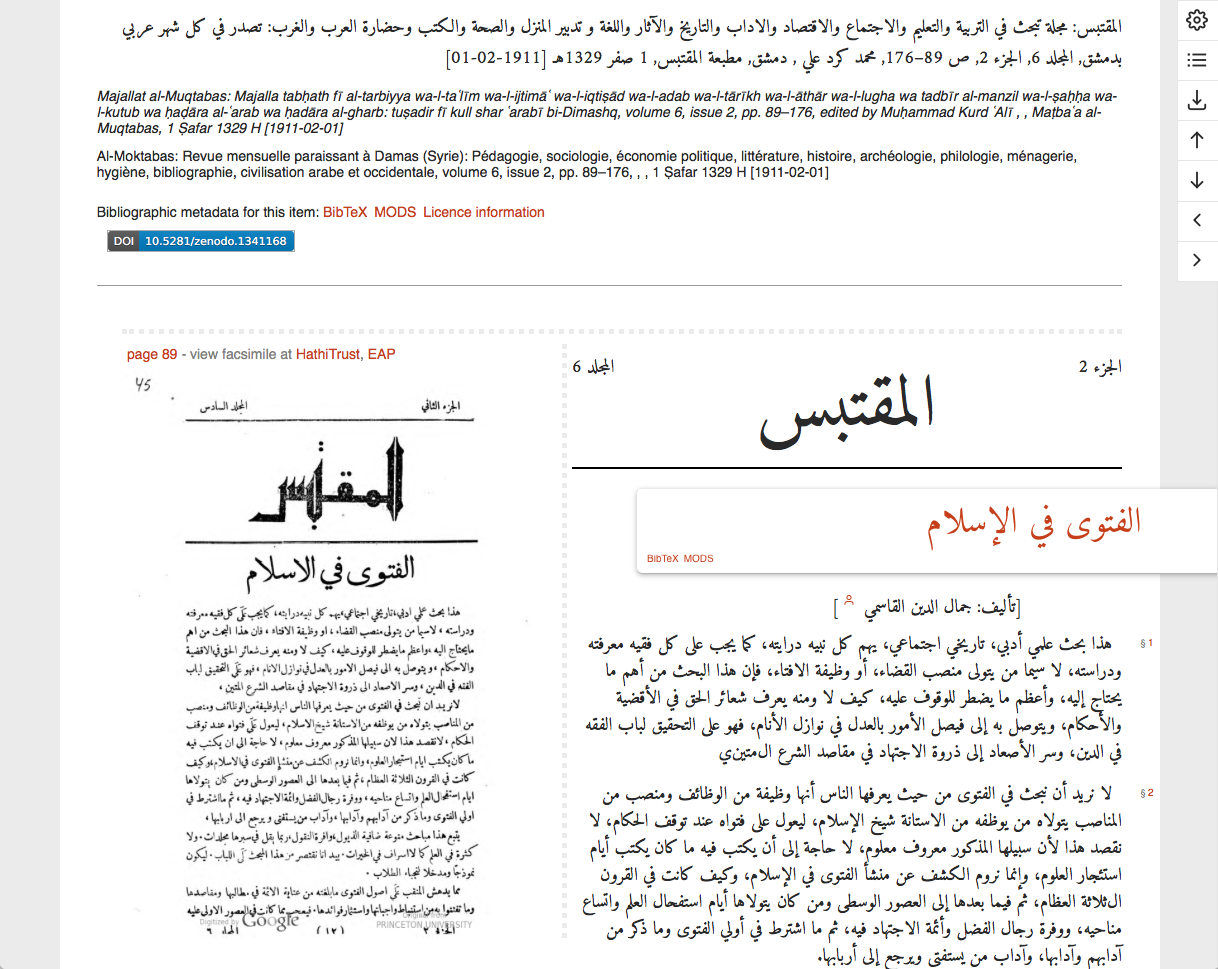
Browser ignorieren das HTML5 Attribut @lang und
stellen Arabisch linksbündig dar
ʿ wird
komplet herausgefiltert, ' und ʾ
nicht)Welche Verzerrungen bildet die Karte ab: Sammlung, Katalogiesierung, Digitalisierung der Wissensinfrastruktur?
<gap/> Katalogisierungsregeln und algorithmische Copyrightbestimmung verstärken Unzugänglichkeiten
Hypothese: geographische Herkunft von Artikeln in einem Periodikum erlaubt Rückschlüsse über seine Bedeutung

<gap/>!





































{kind=link}